A Different View on the Coupon Collector Problem
Once during a meeting in which we were discussing the Fischer-Yates shuffle someone asked:
How many times do we need to run the algorithm to see every permutation?
The simplicity of this question belies the subtlety of its answer. In fact, you can’t actually answer the question as posed. Because Fischer-Yates is a random algorithm, there is no certain answer. For the sake pedagogy, I proposed to answer another question, more suggestive of the probabilistic nature of the original:
What’s the average number of times I need to flip a coin in order to see both sides?
Enter The Coupon Collector Problem
A classic problem in combinatorics called the Coupon Collector Problem(CCP) captures the setting and solution for tackling both the original question and the one I posed. A coupon here is anything of which there are \(m\) distinct types, and the task is to collect at least one of each. For Fischer-Yates, you are collecting all of the \(n!\) permutations of a vector of length \(n\). For the coin, there is a coupon for each side. The general statement of the simplest version of the problem is then:
What is the average number of coupons that need to be collected in order to get a full set?
We assign an arbitrary order and index \(1 \leq i \leq m\). The classic way of getting the result is provided by Wikipedia, which asks you to think about \(t_i\), the number of trials to get the \(i\)-th coupon after you have obtained the previous \(i - 1\) coupons of the full set. What’s the probability of getting the \(i\)-th coupon? Well it’s \(p_i = (m - (i-1))/m\). Then the expected number of trials to get the \(i\)-th is \(1/p_i\), just like the expected number of times to roll a 1 on a six-sided die is 6. The total number of trials, then, is calculated by adding up all of these individual exercises in obtaining coupons. Let’s call this total \(T\):
The last line above defines the \(n\)-th Harmonic Number \(H_n\). I’ll be honest and say that I really don’t like this derivation. It’s clever and fine, but in general I approach problems like this by reasoning about sums of random processes, and this approach isn’t particularly general. At least, to me, it’s very unsatisfying. In any event, I didn’t answer the original question about Fischer-Yates like this. The rest of this article will take you on a circuitous path towards something that is in the end very simple, and very beautiful. I think it also proves that when all else fails, brute force counting can take you a very long way provided you are obstinate enough to keep going.
Flipping a coin to see both sides
So, let’s get back to the coin. We can model the situation as a set of experiments where we collect successive flips. These experiments generate sequences in which the \(n\)-th event is \(H\) or \(T\) and the \(n-1\) other events are all either \(T\) or \(H\) respectively. What would these sequences look like? If we start enumerating the possibilities, we can see patterns appear, depending on how long we run the experiments. For the sequences of length at most \(n\),
It’s interesting that the sequence of length \(k\) is easy to generate from the \((k-1)\)-th by simply prepending the opposite of the terminal token, which doesn’t change. Anyway, what do we do with this sum? Well, if we think about \(H\) and \(T\) as probabilities \(P(H) = p\) and \(P(T) = q = 1 - p\), then \(S_\infty\) better sum to \(1\). So let’s check this by collecting terms:
On the second step, we’ve inserted the series representation for \(\frac{1}{1-x}\) for \(x \lt 1\). Since we’re thinking about \(H\) and \(T\) as probabilities now, we should feel OK about this. Pay special attention to the third step, because we’ll be using it again. Now to calculate \(E[n]\) we interpret \(S_n\) as a probability density, and evaluate the sum:
We start the sum for \(n=2\) since \(S_n\) does not have support for \(n < 2\) (i.e. we can’t possibly see both sides by only flipping the coin once). Regrouping a bit, we see that
For \(p = q\) we have that \(E[n] = 3\). The average number of times you need to flip a fair coin to see both sides is 3. If \(p = 0.25\), then \(E[n] = 4.\bar{33}\). If the coin is only 10% fair, then \(E[n] \approx 10\). If you’re interested in how it varies with \(p\):
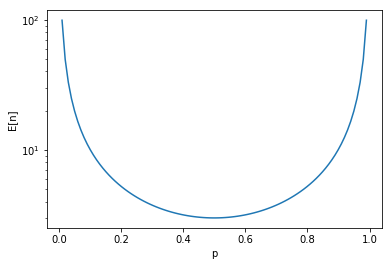
This is maybe a way of estimating if a coin is extremely unfair: build an estimator based on the number flips it takes to see both sides.
Fine for coins, but what about the coupons?
Having solved the problem for \(m = 2\), the next thing to do was to try for \(m > 2\). First, though, we need to think about the \(p_k\), since that’s where it might get hairy. Some options here:
- Naive formulation: all equal probabilities, i.e. \( p_i = 1/m\)
- Singularly hard to get: One distinctive \(p_j\), but all other \(p\)‘s equal
- Anything goes: arbitrary \(p_i\) subject to \(\sum p_i = 1\)
The first is a by far the easiest analyze, and will carry us through to the thing I want to show in this article. For the more general cases (and a less casual approach), see Shank and Yang.
So, the most naive approach to the most naive formulation of the problem is brute-force counting. However, once we started to brute-force count for \(m \gt 2\) things got immediately out of hand. We needed a more systematic approach. You may have noticed that I used the word generate above. That was a hint. Generating Functions are an incredibly useful tool in the toolbox of the brute-forcing recreational combinatorialist. They’re also pretty fear-inspiring to a lot of people.
Since I’m lazy, I tired of brute force counting the sequences at \(m = 3\), but luckily I remembered some advice from Knuth et. al. to use finite automata keep things organized. But before we get to that, it’s first useful to introduce the machinery that we will use when we get there.
The coin redux, this time as a PGF
I’m not going to do justice to generating functions in this space. I recommend Knuth et. al. as a gentle introduction and Wilf if you’re into that kind of thing. But I will give the basic ideas. Imagine that you have a function \(G\) that you are able to expand in a power series. You take the convergence of the series as an article of faith, since that mathematical fact is irrelevant to you. All of the benefits of generating functions come by manipulating the series formally. You never actually need to know what the result of the sum. So, we consider \(G(z)\):
Suppose you also happen to have a recurrence relation for \(c_j = f(\left\{c_i : i < j\right\})\). You may foggily remember how you once you solved differential equations by simply equating coefficients in expansion. You may recall the toolbox for Fourier and Laplace transforms that allowed you to do many computations symbolically. The same thing is going on here. The theory of generating functions allows you to derive from recurrence relation an analytic function \(G(z)\), which can be also expanded into the form above. Then, a closed-form version of \(c_j\) can read off from the \(c_k\) in the series expansion of \(G(z)\) on the other side of the equation.
If this is new to you, I’ll say that it really helps to start with simple recursions and work your way up. But, we’re not going to do any of that here. Instead, we are going to take some liberties and just use the machinery. But I am going to go through the calculations in (maybe excessive) detail to help allay some of the fear that people seem to have of GFs.
The first thing we are going to do is realize that any series sum that involves powers of things can be “converted” to a GF by taking some liberties and making some suitable replacements. Why would we want to do this? Well, it all depends on how you choose to interpret the coefficients. In particular, if you interpret the \(c_k\) as probabilities, then you actually get something that is formally known as a probability generating function (PGF).
Notice a couple of things here: First, that \(G(1) = 1\). Why? well
for everything that we consider to be a probability. Also, notice that
Now this is useful to lazy amateur combinatorialist. Brute-force counting sequences to calculate \(E[n]\) could be replaced by calculating the derivative of the PGF for the process. If only we knew how to create the PGF! Before I show you, let’s observe one more fact about PGFs. Suppose we find ourselves in a situation where we have a PGF that looks something like this
where \(P(z)\) and \(F(z)\) are some analytic functions of \(z\). Observe that
This saves us from having to screw around with partial fractions. Now, let’s use all of this on an unsuspecting sum to see if it works. In light of thinking about PGFs, our original \(S_n\) (from above) in terms of \(T\) and \(H\) is worth talking a look at. So, lets make the replacements \(H \rightarrow pz\) and \(T \rightarrow qz\) and see what happens. This will allow us to promote \(S \rightarrow G(z)\).
If you look back at our earlier calculation of \(E[n]\), you’ll see the same exact result. So, we accomplished nothing, except to convince ourselves that our machinery works.
The coin again, this time as a finite automaton
We return now to the hint that Knuth et. al. gave us about using finite automata to help generate \(S(H,T)\). If we think about the coin problem we’ve been considering, a first stab at at state machine could look something like this.

I’ve labeled the states by number as well. We start in a state \(0\) where we haven’t seen a flip yet. Then we start accumulating flips, moving to \(T_k\) or \(H_k\) initially after a \(T\) or \(H\), then eventually terminating when we get a flip different from the first flip we saw. Now comes the interesting part. Let’s write down the sequence sum, like we did before, this time using the subscript on \(S\) not to index the number of trials, but to index the state \(S_n\):
Here we have identified \(S_{T_{k}H}\) and \(S_{H_{k}T}\) as our terminal states. Solving we see that
This form should be familiar enough now that I don’t have to convince you that this approach worked.
Coupons with Equal Probabilities
We are now prepared to take on the CCP for arbitrary \(m\) with all \(p_i = 1/m\). As before, define a finite automata to describe the process.

Here the states are labeled by the number of distinct coupons we’ve seen. The symbol \(X\) takes the place of the \(H\) or \(T\) and represents the event of seeing a coupon. At the start, there are \(m\) ways we can move to state \(1\). Once we are in state \(1\), there is one way we stay in that state, and \((m-1)\) ways we can move to state \(2\). And so on. Then we can read off \(S\) as before:
Here \(f(X,m_k)\) has been introduced to hold the coefficient. Writing down a few terms for small \(k\) of the recurrence helps us see a closed form
This leads us to conclude that
As before, we make the substitution \( X \rightarrow pz = z/m\), and we promote \(S \rightarrow G(z)\):
Also, as before, we make the substitution \(G=z^{m}/F\) and recall that
Then
Things are looking very promising. Now we evaluate \(Q(1)\)
Interestingly, this means that \(F(1) =1\), which also means that \(F\) also behaves like a PGF. At any rate, we were now left with
By now, we are tired and we resort to some street fighting, Wolfram Alpha-style, which gives us
using the fact that \(\psi^{(0)} = H_{m-1} - \gamma\). Of course, this fact is exactly what Alpha used to give us the answer by re-arranging the sum. Plugging this all in, we finally get
using \(H_m = H_{m-1} + 1/m\). This was our goal.
Now to answer the original question for the equally probable Coupons. In general we can get a one-sided confidence interval for \(n\), the number of times we “roll” until success, by using \(E[n]\) and Markov’s inequality. If we calculated the variance using the formulas above, we could use Chebyshev’s to get a two sided confidence interval and a tighter bound. Anyway,
Setting \(1/k = 0.05 \Rightarrow k = 20\). For example, for a six-sided die, for \(\epsilon = kmH_m\),
For a permutation of order \(6\), the 95% threshold is \(\approx 200000\).
Finally, for large \(m\),
In my weird and twisted way, this is a much more satisfying approach to answer the original question. I’ve always been interested to see how we can apply this to arbitrary finite automata. For instance, I’m curious to use this technique on the KMP Algorithm. I’m a fan of David Eppstein’s Notes on algorithms from long ago in internet time, particularly where he shows a state machine for KMP:
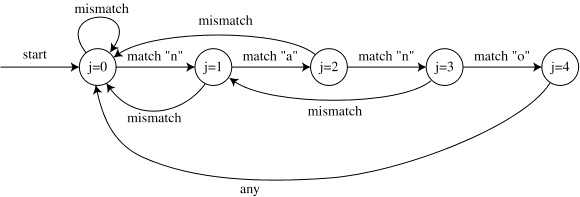
Conclusion
Even though I don’t like the canonical explanation, the Wikipedia page on CCP has many useful links. One my favorites in particular is by Flajolet et. al.. That’s a truly systematic approach to the problem, and shows interesting connections to other allocation problems.
Dan Jacob Wallace takes different approach that I enjoyed reading.
Read more in Math and Science
